
MarineLives New Year Wishes
This post began as a discussion on twitter on how IIIF could help the MarineLives project achieve their goals on collecting and transcribing historical content related to the manuscripts of the High Court of Admiralty 1627-1677. You can read more about their mission on the MarineLives wiki.
The MarineLives 2018 New Years Wish list is as follows:
-
A world in which we could download a single manuscript image from an archival, library or museum website; transcribe it, or add key words; then lob into the Commons. All data recorded with the image. And a Universal Search Tool would search all the content.
-
A manuscript image uploading & exchange site for PhD students to upload & share images taken as part of their research work, which would otherwise be unpublished.
-
A C17th combination of ZoomInfo & LinkedIn to create, improve & make available prosopographies by automatically aggregating historical web & archival sources.
-
A digital camera which saves each new image of a manuscript page with its archival reference number, not a number file name [e.g. TNA HCA 13/53 f.12r] - We could upload 1000 images a day to our laptops * search for them by archival reference & find instantly.
Some of these wishes fall squarely into what IIIF offers and the others may be assisted by some related technologies. I will split the first wish into its parts:
1-A: A world in which we could download a single manuscript image from an archival, library or museum website.
Starting with the first one IIIF supports the transcription of images without requiring the images to be downloaded. This can make it easier for institutions including Archives, Libraries and Museums to make their images available but will also help in linking transcriptions back to a source image. IIIF provides support for transcriptions by using the Web Annotations W3C specification. Web annotations allow annotation on many different types of resources including images, web pages and videos. It is an open format which allows the interoperability of annotations created by different systems.
Below is a video from Stanford demonstrating how to take a reference to two IIIF objects (one from Stanford and one from the Bodleian Library in Oxford) and drag them into a third viewer Mirador.
1-B: Transcribing images
The Mirador viewer allows the comparison of images from different locations and also supports transcription of these images through its annotation interface and this is demonstrated in the following video:
Mirador supports both transcription and tagging type annotations. Transcribing through Mirador does not require hosting of the images separately as you can rely on the IIIF Image and Presentation API to annotate the images while they are stored and published by the institution. There is a public demo of Mirador available that allows you to load remote Manifests and start transcribing them into a local browser store. For persistent annotations you would have to look at installing an annotation store and a list of options can be found on the IIIF Awesome List.
There are also other options for creating annotations including various Crowdsourcing systems mentioned in the Awesome List issue. All of these should allow the import of IIIF image and presentation endpoints and allow their transcription. While working at the National Library of Wales (NLW) I was involved in the development of a Crowdsourcing system with Digirati. I gave a presentation in the Rome IIIF conference demonstrating the crowdsourcing of Photographs from North Carolina State University using the NLW crowdsourcing system. A video showing the setup is available on youtube. This video hopefully demonstrates the idea of taking content from a third party and transcribing using IIIF tools.
1-C: then lob [annotations] into the Commons. All data recorded with the image.
Annotations created through Mirador or the other crowdsourcing systems will likely be in either the Web Annotations format or the precursor Open Annotations. There isn’t as far as I know a way to convert these annotations to something that could go on Wiki Commons but as the annotations are stored as JSON-LD it should be possible to convert them to other formats. An alternative to submitting the annotations to Commons is to submit the annotations back to the institution that is publishing the IIIF resource. Specifying this protocol is part of the work of the IIIF Discovery group but there is already an early proof of concept created between Jeff Witt (Loyola University Maryland) and e-Codices detailed in Jeff’s blog. This and Jeff’s further work on Linked data Notifications offer an exciting option for the future where institutions can take back the work of volunteers and integrate the valuable data generated into their existing systems.
1-D: And a Universal Search Tool would search all the content.
There are many institutions which implement IIIF and some of these can be found on the IIIF website but if you are working with content that isn’t IIIF accessible then there are some alternatives detailed in the next section. The IIIF Discovery group are looking at ways to make it easier to find IIIF institutions and their images but the ‘Universal Search Tool’ mentioned is likely out of scope. The group does aim to put the protocols in place to allow someone to create this type of discovery tool particularly for annotations.
2. Image upload and exchange
There is a little known feature with the IIIF presentation API that allows you describe non IIIF images. This could allow you to create a IIIF Manifest that links to images hosted on Wiki Commons or Flickr and then load this manifest into Mirador for transcription. This is a relatively unused feature of IIIF but is recently supported in the Universal Viewer and Mirador but may not be supported in the other crowd sourcing solutions mentioned above. Tom Crane has been pushing for this to be supported in the IIIF viewers and created an application which uses static images from Wikipedia. This would allow you to transcribe content using IIIF viewers without the source institution supporting IIIF.
It is also possible to support more IIIF image API functions by either using static tiles which can be generated by Simeon’s tile generator or looking at hosting a full IIIF compliant image server.
Although its possible to use non IIIF images in theses ways there are a number of reasons why it is preferable to use an institution’s IIIF image and manifest:
- Single identifier for an image or object
Using IIIF and transcribing IIIF resources encourages the re-use of shared identifiers particularly the Canvas URI which is an identifier for a particular image and the target of most IIIF annotations. By sharing the canvas ID multiple users can transcribe the same resource and their annotations can be shared and combined. By publishing a separate manifest with new Canvas IDs it means the annotations are only associated with that instance so it may not be possible to combine then with other transcriptions or with the source content in the institution.
- Shared coordinate space
As well as a canvas URI, the canvas also specifies the width and height of the image and this is usually the width and height of the source Tiff or JP2. It means annotations on the canvas will always be located in the correct place even when viewing the image at different sizes. If you were to transcribe a downloaded jpg or a new capture the institution and other users of the content may not have the information to transpose references to coordinates of the derivative jpg back to the source tiff or jp2. Coordinates for annotations are particularly important when implementing the IIIF Search API which allows users to search transcribed or generated text.
With the above points noted, it isn’t always possible to have IIIF images provided by an institution and using static images with a IIIF Manifest will allow some of the IIIF features to be used.
3. Aggregating prosopographies
This falls out of the scope of IIIF but IIIF will allow a better aggregation of the source of some of these prosopographies. Europeana is a good example of an aggregator which harvests IIIF manifests from institutions and is able to show a rich interface using the IIIF images remotely:
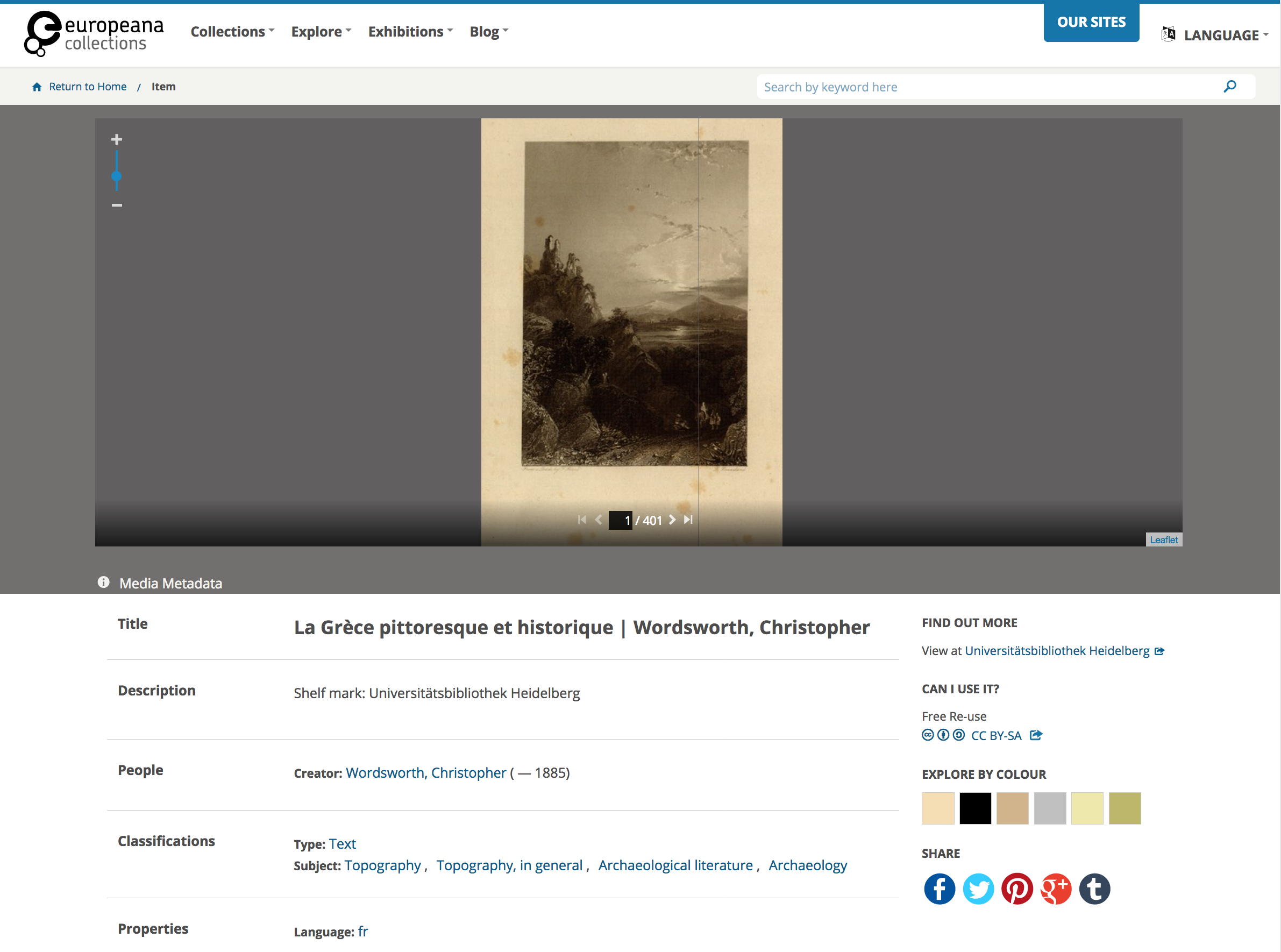
Wikidata offers an exciting place to aggregate prosopographies but only if they meet the notoriety criteria. Other than that it is going to be difficult to create an aggregator of this type. Possibly the way to make this feasible is to make prosopographies available as Linked Open Data so they can be aggregated at a future date. The issue with aggregation is how to disambiguate different entries and ensure correctly linked entries are created. I have tried some of this type of disambiguation with the NLW Shipping Records and appreciate how difficult it can be.
4. Digitising with the original archival reference number
As mentioned in the Image upload and exchange section it is preferable to use an institution’s IIIF resource rather than host a separate copy of the image. This is particularly relevant with identifiers including archival reference numbers. Typically institutions maintain many identifiers for a digital image including; catalogue numbers, reference numbers, digital image filenames and repository identifiers. It can be difficult to transpose between identifiers but using the Canvas ID as mentioned previously can allow institutions to use this identifier as the master for the published image. The reference number in the example ‘TNA HCA 13/53 f.12r’ looks to be a combination of the identifier for the archival object with a page number appended. It can be difficult for a machine to split this identifier to work out which image is being referenced. With a Canvas URI there is a defined behaviour and API which allows it to be machine processed (if the machine also has a reference to the manifest it came from). Identifiers like the example in the wish list are important for users to be able to navigate the material and in a IIIF manifest the first portion of the identifier ‘TNA HCA 13/53’ would be present in the metadata section of the manifest and the ‘f.12r’ would be the canvas label. Neither the manifest metadata or canvas label would be expected in the IIIF implementation to be machine processable.
If its not possible to have a IIIF image from the institution then the images would likely have short filenames and new canvas Ids would be minted. In the NLW we handled the association between identifiers and digital images by using a workflow management system developed internally called Wombat. This allowed you to associate archival reference numbers with a book or file and also filenames with page labels. We relied on the public catalogue to allow users to search archival reference numbers and get access to digital objects.